개인적으로 새로운 언어를 공부하는 것은 너무나 재미있습니다. 새로운 대륙을 향해 돛단배를 몰고가는 것과 같습니다. 어디로 갈지 모르지만, 미지의 세계를 목표로 출발하는 마음은 셀렘이라는 감정일 것입이다.
이 글에서는 두 가지 언어의 기능, 장단점, 코드 예제를 통해 이 두 가지 언어를 비교해 보겠습니다. 이 글을 읽고 나면 어떤 프로그래밍 언어가 여러분의 필요에 맞는지 더 잘 알 수 있기를 바랍니다.
엘릭서
Elixir는 Erlang VM에서 실행되는 함수형 프로그래밍 언어입니다. Ruby와 동일한 스크립팅 스타일을 사용하지만, Ruby는 객체 지향 언어 패러다임을 따르고 Elixir는 함수형 패러다임을 따른다는 차이점이 있습니다.
특징
- Elixir는 처음부터 동시성을 가장 잘 처리하는 데 중점을 두었습니다.
- Elixir는 함수형 프로그래밍 패러다임을 따르기 때문에 반복적인 코드 없이 쉽게 작성할 수 있는 언어를 만들기 위해 노력합니다.
- Elixir는 내결함성(결함 감내 시스템: Fault tolerant system)을 갖도록 설계되어 문제가 발생했을 때 재시작할 수 있습니다.
- Elixir는 확장성이 뛰어납니다. 예를 들어, GPU에서 실행할 수 있습니다.
- 대화형 또는 컴파일된 형태로 Repl에서 Elixir를 실행할 수 있습니다.
Elixir는 확장 가능하고 내결함성 있는 애플리케이션을 구축하는 데 적합한 강력하고 다재다능한 프로그래밍 언어입니다. 함수형 프로그래밍 패러다임, 동시성 기능, Erlang 에코시스템과의 호환성 덕분에 다양한 도메인 및 산업에서 널리 사용되고 있습니다.
엘릭서를 사용하는 곳
Elixir는 Pinterest, Bleacher Report, Discord를 비롯한 다양한 기업과 조직에서 사용하고 있습니다. 대량의 트래픽을 처리할 수 있고 내결함성이 뛰어나 웹 애플리케이션과 분산 시스템을 구축하는 데 널리 사용됩니다.
문서에 따르면 주목할 만한 Elixir 사용자는 다음과 같습니다.
- 펩시코: PepsiCo는 소비재 판매를 위한 전자상거래 도구로 Elixir를 사용한다고 보고했습니다. 이들은 Elixir가 강력하고, 간단하며, 배우기 쉽고, 효율적이라는 점을 발견했습니다. Elixir를 사용한 펩시코 지점은 2019년에 20억 달러의 수익을 올렸습니다.
- Spotify: Spotify는 백엔드 개발에 Elixir를 사용합니다. 방대한 데이터베이스와 수많은 활성 사용자로 인해 초당 수천 건의 요청을 처리하고 처리할 수 있는 기술이 필요했습니다. Elixir는 필요한 수준의 동시성을 제공하여 세계적인 음악 및 엔터테인먼트 플랫폼으로 성장하는 데 도움을 주었습니다.
- Discord: 게이머를 위한 채팅 플랫폼인 Discord 역시 Elixir를 사용하고 있습니다. 대용량 데이터와 엄청난 트래픽을 처리할 수 있는 기술이 필요했습니다. Elixir를 통해 수백만 명의 사용자도 실시간으로 처리할 수 있었습니다. Elixir는 기술 스택의 주요 언어가 되었습니다.
- WhatsApp: 전 세계에서 가장 인기 있는 메시징 앱 중 하나인 WhatsApp은 Elixir를 사용합니다. 이 애플리케이션은 처음에 Erlang으로 완전히 작성된 후 Elixir 기반 요소를 도입하여 개선되었습니다. Elixir는 WhatsApp이 방대한 트래픽과 대량의 요청을 처리하는 데 도움이 됩니다.
- Heroku: Elixir와 Phoenix 프레임워크를 사용하여 대시보드를 구동하는 Heroku
Elixir 장단점
Elixir의 장점
- 내결함성(결함 감내 시스템: Fault tolerant system): 동시성을 사용하면 시스템은 종종 많은 문제에 직면합니다. 이러한 문제 중 하나는 하드웨어 오류, 소프트웨어 버그, 네트워크 문제 또는 리소스 제약으로 인해 시스템의 일부가 다운될 수 있다는 것입니다. Elixir는 시스템의 안정성과 장애에 대한 복원력을 보장하는 데 탁월합니다.
- 확장성(Scalability): Elixir는 동시성 시스템 개발에 항상 우선순위를 두어온 Erlang VM(BEAM)에서 실행되므로 확장성이 뛰어납니다. 이 언어는 서로 통신하는 경량의 격리된 스레드에서 실행됩니다. 또한 Elixir를 사용하여 여러 머신에서 프로세스를 실행하고 통신할 수 있으므로 수평적 확장성을 달성할 수 있습니다.
- 웹 API
- 강력하고 동적으로(런타임에 확인) 입력됩니다.
- 소프트 실시간 서비스는 챗봇이나 Google 문서와 같은 소켓 연결로 구축할 수 있습니다. 하드 실시간 서비스에는 적합하지 않습니다(두 서비스의 차이점은 여기에 있습니다).
- 높은 확장성과 내결함성 지원을 제공합니다.
- 동시성은 액터 모델을 기반으로 합니다. 이는 Agha의 클래식 액터 모델과 대체로 유사합니다. 이러한 유형의 액터 모델을 프로세스 기반 액터라고 합니다. 이는 시작부터 완료까지 실행되는 계산으로 정의됩니다. 대신 Agha의 클래식 액터 모델은 액터를 거의 행동의 상태 머신과 그 사이를 전환하는 로직으로 정의합니다. 프로세스 기반 액터 모델은 에릭슨에서 Erlang을 개발하면서 처음에 개발되었습니다.
- 또한 패턴 매칭을 지원하므로 더 복잡한 데이터 유형을 분해하는 데 도움이 될 수 있습니다.
- 안정적인 라이브러리와 지원 커뮤니티가 있지만 Nodejs나 Python과 같지는 않지만 충분히 괜찮은 수준입니다(인기 있는 커뮤니티는 거의 없음).
- 개발자 경험이 좋습니다.
Elixir의 단점
- 소규모 커뮤니티: Elixir 프로젝트에서 문제가 발생하면 커뮤니티가 상대적으로 작기 때문에 해결책을 찾거나 질문에 대한 답을 찾기가 어려울 수 있습니다.
- 구직 시장에서 낮은 수요: 향후에는 달라질 수 있지만, 개발자 커뮤니티의 많은 부분에서 숙련된 Elixir 개발자에 대한 수요가 적기 때문에 구직 시장에서 이들을 찾기가 어려울 수 있습니다.
Exlixir의 코드
Elixir의 코드는 스레드보다 가볍고 저렴한 프로세스를 통해 실행되므로 수천 개 또는 수백만 개의 프로세스를 생성할 수 있습니다. Elixir에서 프로세스는 격리되어 메모리를 공유하지 않고 서로에게 메시지를 전송하여 통신합니다.
아래 코드 블록에 따라 함수를 인수로 받고 프로세스 식별자(PID)를 반환하는 spawn/1 함수를 사용하여 새 프로세스를 생성하려면 다음과 같이 하세요:
process_pid = spawn(fn ->
IO.puts("Starting process")
end)
IO.puts("PID: #{inspect(process_pid)}") # PID: #PID<0.98.0>
한 프로세스에서 다른 프로세스로 메시지를 보내려면 수신자의 PID와 메시지를 지정하여 send/2 함수를 사용할 수 있습니다. 메시지를 받으려면 지정된 패턴과 일치하는 메시지가 올 때까지 기다리는 receive/1 함수를 사용할 수 있습니다. 메시지는 패턴과 순차적으로 매칭되므로 메시지 내용에 따라 수신할 메시지를 선택할 수 있습니다.
엘릭서에서 메시지를 보내는 방법은 다음과 같습니다:
send(process_pid, {:print_hello})
Elixir 프로세스는 동시에 실행되므로 겹치는 방식으로 실행될 수 있지만 반드시 여러 CPU 코어에서 병렬로 실행되지는 않습니다. 동시성 모델은 프로세스가 메시지를 전달하여 통신하는 액터 모델을 기반으로 합니다. 이 모델은 공유 상태를 없애고 메시지를 통해 통신하는 격리된 프로세스에 집중함으로써 동시 프로그래밍을 단순화합니다.
Elixir는 작업을 동시에 실행하기 위해 서로 다른 프로세스에서 작업을 예약하는 Task 모듈을 제공합니다. Task 모듈을 사용하여 여러 작업을 병렬로 실행하는 방법은 다음과 같습니다:
tasks = [
Task.async(fn -> IO.puts("Doing work 1") end),
Task.async(fn -> IO.puts("Doing work 2") end)
]
for task <- tasks do
Task.await(task)
end
주어진 URL에 대한 모든 링크를 찾는 웹 크롤러를 만들어 보겠습니다.
우리가 구축하는 크롤러는 주어진 URL의 모든 링크를 가져오는 것을 목표로 주어진 URL에 대한 모든 링크를 크롤링합니다. 피해야 할 사항은 다음과 같습니다:
- 중복 크롤링 링크 없음
- 크롤러가 동시에 실행되며 다음과 같이 구성할 수 있습니다.
- 크롤러의 실행 시간과 메모리 사용량 비교
이 튜토리얼에는 모든 코드가 포함되어 있지는 않지만 가장 중요한 부분을 보여드리겠습니다. 먼저 Elixir는 함수형 언어이므로 웹사이트를 재귀적으로 크롤링할 것입니다:
def run(start_url, scraper_fun, max_concurrency) do
Stream.resource(
fn -> {[start_url], []} end,
fn
{[], _found_urls} ->
{:halt, []}
{urls, found_urls} ->
{new_urls, data} = crawl(urls, scraper_fun, max_concurrency)
new_urls =
new_urls
|> List.flatten()
|> Enum.uniq()
|> Enum.reject(&diff_host?(URI.parse(start_url), &1))
|> Enum.map(&to_string/1)
|> Enum.reject(&Enum.member?(found_urls, &1))
{data, {new_urls, new_urls ++ found_urls}}
end,
fn _ -> IO.puts("Finished crawling for '#{start_url}'.") end
)
end
defp crawl(urls, scraper_fun, max_concurrency) when is_list(urls) do
urls
|> Task.async_stream(&crawl(&1, scraper_fun, max_concurrency),
ordered: false,
timeout: 15_000 * max_concurrency,
max_concurrency: max_concurrency
)
|> Enum.into([], fn {_key, value} -> value end)
# |> Enum.map(&crawl(&1, scraper_fun)) # To run without concurrency
|> Enum.reduce({[], []}, fn {scraped_urls, scraped_data}, {acc_urls, acc_data} ->
{scraped_urls ++ acc_urls, scraped_data ++ acc_data}
end)
end
따라서 크롤러는 중복 링크를 필터링하여 크롤링하고, 크롤러를 현재 도메인으로만 제한하며, 동시성으로 실행합니다. 다음은 Elixir에서 크롤러의 메모리 사용량입니다:
Rust
Rust는 정적이고 강력한 타이핑 및 컴파일 언어입니다. 그 결과 커뮤니티가 매우 빠르게 성장했습니다.
- 구조는 완전히 객체 지향이 아닌 객체 지향 위에 존재합니다. Java의 인터페이스와 같은 특성이 존재합니다. 상속은 없지만 a/is 모델을 사용하여 상속을 지원합니다.
- 컴파일 시 가비지 컬렉션으로 인해 메모리 안전성을 제공하고 성능이 향상됩니다.
- Rust에는 가비지 컬렉션이 없지만 차용 검사기가 있습니다.
- 멀티 스레드가 스레드 안전하지 않은 경우 컴파일 시 유형 오류가 발생합니다.
Rust 의 장점
- 강력한 타입 시스템 언어
- 동시성이 가능하며 행위자 모델을 따릅니다.
- 컴파일러는 훌륭하고 사전에 상황을 파악합니다.
- 배포를 위해 출력에 정적 바이너리를 생성합니다.
- CPU 집약적인 애플리케이션과 같이 효율성과 성능이 필요한 시스템을 위한 시스템입니다.
- Async io는 Tokio 모듈과 함께 안정화되고 있습니다.
- 사용하지 않는 기능에는 비용을 지불하지 않습니다.
- 추상화 비용이 들지 않습니다.
Rust의 단점
- 학습 곡선이 더 높고, 코드 작성이 복잡합니다.
- 성장이 필요한 라이브러리와 커뮤니티
- 느린 컴파일러
- 100% 자체 지원 컴파일러는 아니며 LLVM 컴파일러에서 구현됩니다.
Elixir와 Rust 비교
Rust는 안정적이고 효율적인 소프트웨어를 구축하는 프로그래밍 언어입니다. Rust의 초점 중 하나는 프로그램이 메모리 안전성을 보장하는 것입니다. Rust는 Elixir나 Go처럼 스레드나 코루틴을 지원하지는 않지만, 런타임을 구현하기 위한 하위 수준의 빌딩 블록을 제공합니다.
오늘은 동시 런타임을 빌드하지는 않겠지만, Rust에서 가장 많이 사용되는 비동기 런타임 중 하나를 사용하겠습니다: Tokio를 사용하겠습니다. 비동기와 동시성은 다르지만, Tokio 라이브러리의 일부를 사용하여 동시 런타임처럼 작동하도록 만들 수 있습니다.
다음은 Tokio 상자를 사용하여 동시 프로그램을 만드는 방법입니다:
- 프로세스: Tokio에서 프로세스를 실행하려면 tokio::spawn을 사용할 수 있습니다. Tokio는 현재 스레드에서 실행할지 다른 스레드에서 실행할지 처리합니다. 또한 하나의 스레드에서만 실행하거나 여러 스레드에서 실행하도록 구성할 수도 있습니다.
- 메시지: 프로세스 간 통신을 위해, Gol에서 채널처럼 작동하는 Tokio 메시지 채널 모듈 tokio::sync::mpsc를 사용할 수 있습니다.
- 공유 상태: 공유 상태는 위험한 작업이지만 다행히도 Rust는 우리가 올바르게 수행하고 있는지 확인하는 데 도움을 줄 것입니다. Tokio를 사용하면
tokio::sync::Mutex를 사용하여 공유 상태에 안전하게 액세스할 수 있습니다.
다음은 Tokio를 사용한 간단한 비동기 작업의 예입니다:
use tokio::time::{sleep, Duration};
#[tokio::main] // 새 Tokio 런타임을 시작합니다.
async fn main() {
let task = tokio::spawn(async {
// 일부 작업을 시뮬레이션합니다.
sleep(Duration::from_millis(50)).await;
println!("작업이 완료되었습니다");
});
// 작업이 완료될 때까지 기다림
task.await.unwrap();
}
이 예제에서 tokio::spawn은 Tokio 런타임에서 새 작업을 시작하고, tokio::time::sleep은 일정 시간 후에 완료되는 퓨처를 생성합니다. await 키워드는 이러한 퓨처가 완료될 때까지 기다리는 데 사용되지만, 스레드를 차단하지 않고 다른 작업을 실행할 수 있도록 허용합니다.
동시성 프로그래밍에서는 여러 작업 간에 상태를 공유해야 하는 경우가 많습니다. 이를 위해 일반적으로 메시지 전달을 사용하는 것이 더 안전하며 코드를 더 쉽게 추론할 수 있기 때문에 선호되는 방법입니다. 하지만 상태 공유가 필요한 경우도 있습니다.
작업 간에 상태를 공유하려면, std::sync의 일부인 Arc를 제외한 tokio::sync 모듈의 일부인 Arc, RwLock, Mutex 및 Semaphore와 같은 유형을 사용할 수 있습니다. 이러한 유형을 사용하면 여러 작업에서 변경 가능한 상태를 안전하게 공유할 수 있습니다:
- Arc(원자 참조 카운트): Arc를 사용하면 작업이나 스레드에서 공유할 모든 타입이나 구조체를 래핑할 수 있습니다. 예를 들어 Arc는 User를 힙에 저장합니다. 그런 다음 해당 인스턴스를 복제하여 힙에서 User를 참조하는 새 Arc 인스턴스를 만들 수 있습니다.
- Mutex(상호 제외): 한 번에 최대 하나의 스레드만 일부 데이터에 액세스하거나 변경할 수 있도록 합니다.
- RwLock(읽기-쓰기 잠금): 쓰기자가 잠그지 않는 한, 여러 작업 또는 스레드가 데이터를 읽을 수 있도록 합니다.
- 세마포어: 세마포어는 동시성에서와 같이 워커를 구현하는 데 사용할 수 있습니다. 예를 들어, 데이터가 1,000개인데 1,000개의 워커를 스폰하고 싶지 않은 경우 세마포어를 사용하면 스폰할 워커 수를 제한할 수 있습니다. 세마포어는 워커가 많다고 해서 프로젝트가 더 빨리 작동하는 것은 아니기 때문에 유용합니다.
Arc와 Mutex의 예제
use std::sync::Arc;
use tokio::sync::Mutex;
use tokio::spawn;
#[tokio::main]
async fn main() {
let data = Arc::new(Mutex::new(0));
let data1 = Arc::clone(&data);
let task1 = spawn(async move {
let mut lock = data1.lock().await;
*lock += 1;
});
let data2 = Arc::clone(&data);
let task2 = spawn(async move {
let mut lock = data2.lock().await;
*lock += 1;
});
task1.await.unwrap();
task2.await.unwrap();
assert_eq!(*data.lock().await, 2);
}
이 예제에서는 일부 데이터를 저장하기 위해 Arc<Mutex<i32>>가 생성됩니다. 그런 다음 각각 데이터를 증가시키는 두 개의 작업이 생성됩니다. Mutex는 한 번에 하나의 작업만 데이터에 액세스할 수 있도록 보장하기 때문에 데이터 경합이 발생하지 않으며 최종 결과는 예상대로 나타납니다.
한 가지 주목할 점은 Tokio에서 제공하는 잠금(예: Mutex 및 RwLock)은 비동기식이며, 경합이 발생할 때 전체 스레드를 차단하지 않는다는 점입니다. 대신 현재 작업만 차단하여 다른 작업이 동일한 스레드에서 계속 실행될 수 있도록 합니다.
이제 Rust와 Tokio를 사용해 간단한 웹 크롤러를 만들어 보겠습니다. 먼저 크롤러를 실행할 특성을 정의해 보겠습니다:
use crate::error::Error;
use async_trait::async_trait;
pub mod web;
#[async_trait]
pub trait Spider: Send + Sync {
type Item;
fn name(&self) -> String;
fn start_url(&self) -> String;
async fn scrape(&self, url: String) -> Result<Vec<Self::Item>, Error>;
}
Spider를 구현합니다.
impl WebSpider {
pub fn new(start_url: String, worker: usize) -> Self {
let http_timeout = Duration::from_secs(4);
let http_client = Client::builder()
.timeout(http_timeout)
.user_agent(
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:47.0) Gecko/20100101 Firefox/47.0",
)
.pool_idle_timeout(http_timeout)
.pool_max_idle_per_host(worker)
.build()
.expect("WebSpider: Building HTTP client");
WebSpider {
http_client,
start_url,
}
}
}
#[async_trait]
impl super::Spider for WebSpider {
type Item = String;
fn name(&self) -> String {
String::from("WebSpider")
}
fn start_url(&self) -> String {
self.start_url.to_string()
}
async fn scrape(&self, url: String) -> Result<Vec<String>, Error> {
println!("Scraping url: {}", &url);
let raw_url = Url::parse(&url)?;
let host = raw_url.scheme().to_owned() + "://" + raw_url.host_str().unwrap();
let start = Instant::now();
let body_content = self.http_client.get(&url).send().await?.text().await?;
let seconds = start.elapsed().as_secs_f64();
if seconds > 3.0 {
println!(
"Parsing res body: {} in \x1B[32m{:.2}s\x1B[0m",
&url, seconds
);
}
let parser = Html::parse_document(body_content.as_str());
let selector = Selector::parse("a[href]").unwrap();
let links: Vec<String> = parser
.select(&selector)
.filter_map(|element| element.value().attr("href"))
.filter_map(|href| {
let parsed_link = raw_url.join(href);
match parsed_link {
Ok(link) => {
let mut absolute_link = link.clone();
absolute_link.set_fragment(None);
absolute_link.set_query(None);
if absolute_link.to_string().starts_with(&host) {
Some(absolute_link.to_string())
} else {
None
}
}
Err(_) => None,
}
})
.collect();
Ok(links)
}
}
실행
$ ./crawler_rust --work 10 --url https://react.dev
Elixir, Rust 성능의 벤치마크
지금까지 웹 크롤러를 Rust, Elixir에 구현했습니다. 이제 각각의 성능을 확인하기 위해 벤치마크를 실행해 보겠습니다. 작업을 완료하는 데 걸리는 시간과 테스트 중에 사용되는 메모리 양이라는 두 가지를 측정하고자 합니다. 크롤러는 https://react.dev 도메인의 모든 링크를 가져옵니다. 127개의 링크를 가져올 것으로 예상됩니다.
시간 측정 벤치마크
10개의 동시성 작업자를 사용하여 각 웹 크롤러가 링크를 가져오는 데 걸린 시간은 다음과 같습니다:
HTTP 요청을 수행하는 데 시간이 걸립니다. 이는 각 연결에서 SSL/TLS 핸드셰이크가 생성되기 때문입니다. 기본 Go HTTP 라이브러리는 이 두 가지를 동시에 실행하기 때문에 이 시나리오에서 Go의 성능이 가장 우수합니다.
Elixir와 Rust를 모두 최적화하여 TLS/TLS 핸드셰이크를 한 번만 생성하고 워커 전체에서 사용하도록 할 수 있습니다:
TLS/SSL 핸드셰이크를 한 번만 만들고 작업자 전체에서 사용해야 합니다:
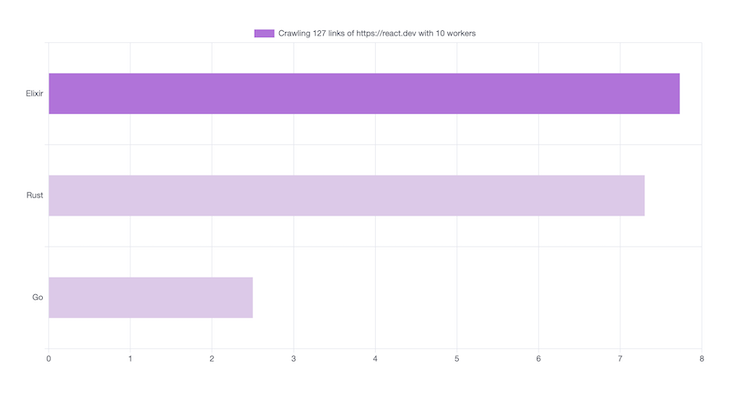
다음은 50명의 워커의 결과입니다. 더 많은 동시성 워커를 사용한다고 해서 크롤러의 속도가 향상되는 것은 아니며, 네트워크 지연에 의해 제한되기 때문입니다
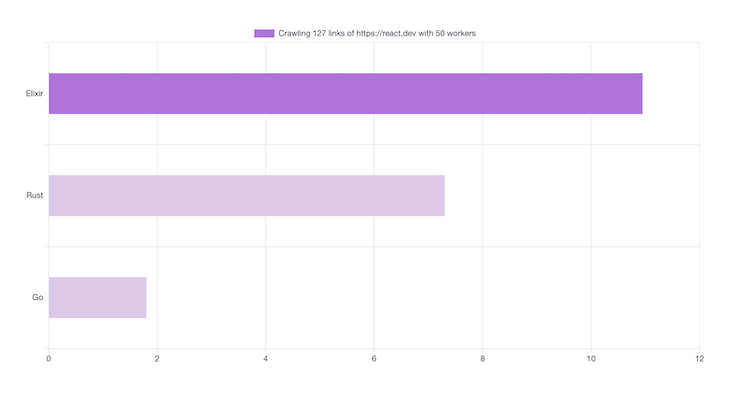
다음은 동시성(Concurency)를 조외한 밴치마크 입니다.
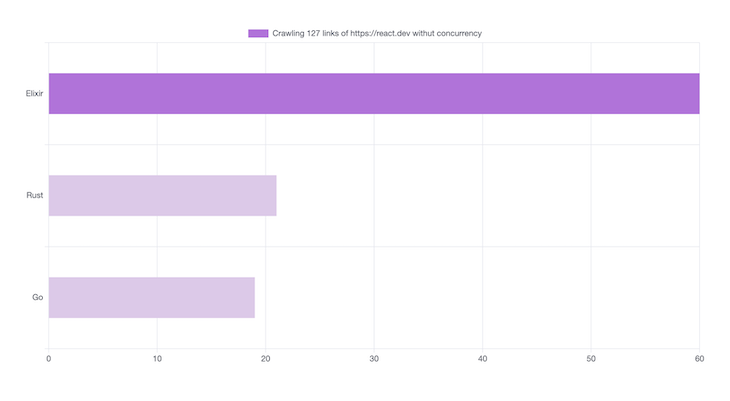
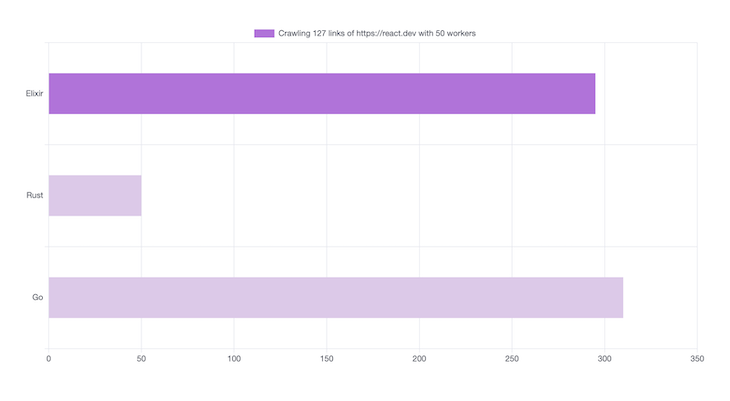
메모리 사용 밴치마크
메모리 사용량과 관련해서는 흥미로운 점이 있습니다:
- Elixir: 295MB
- Rust: 50MB
메모리 사용량에서는 Rust가 더 나은 성능을 보이는 반면, Elixir의 성능은 비슷하게 떨어지는 것을 알 수 있습니다:
결론
이 튜토리얼에서는 Elixir, Rust로 동시 프로그램을 실행하는 방법을 배웠습니다. 각 언어마다 동시성을 처리하는 방법에 대한 고유한 아이디어가 있지만, Go의 기본 라이브러리는 동시성을 훌륭하게 지원하지만 메모리를 많이 사용한다는 것을 알 수 있었습니다. 이는 힙에 메모리를 할당하고 가비지 컬렉션을 사용하여 메모리를 정리하기 때문입니다. 이로 인해 GC가 정리를 수행할 때 메모리 사용량이 많아지고 일부 결함이 발생할 수 있습니다.
Elixir에서는 프로세스를 스폰하고 프로세스 간 공유 상태를 관리하는 것이 얼마나 쉬운지 확인했습니다. 하지만 동시에 Elixir에서 동시 프로그램의 성능을 향상시키는 것은 쉽지 않습니다. Elixir는 가비지 컬렉션을 사용해 메모리를 관리하기 때문에 Go과 비슷한 성능을 발휘합니다.
Rust로 동시 프로그램을 작성하는 것은 쉽지 않지만, Rust의 소유권 및 타입 시스템 덕분에 메모리 안전성을 확보할 수 있다는 이점이 있습니다. Rust는 가비지 컬렉션을 사용하지 않기 때문에 가비지 컬렉션을 사용하는 골랑이나 엘릭서보다 메모리 사용 측면에서 더 효율적입니다.
이 글의 전체 소스코드는 여기에서 확인할 수 있습니다(https://github.com/ahmadrosid/elixir-go-rust). 궁금한 점이나 공유하고 싶은 추가 정보가 있으면 언제든지 알려주세요.