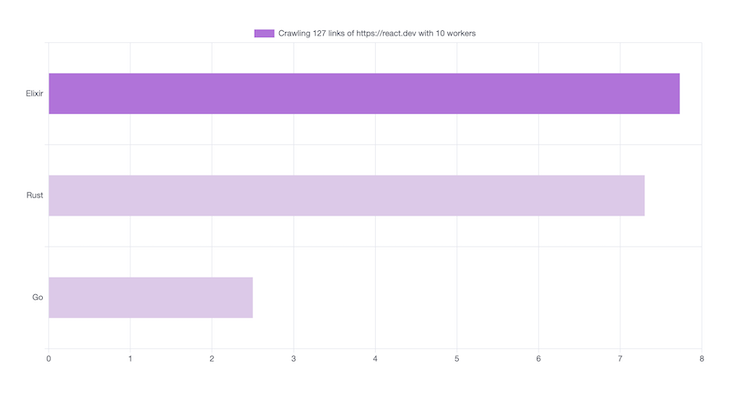
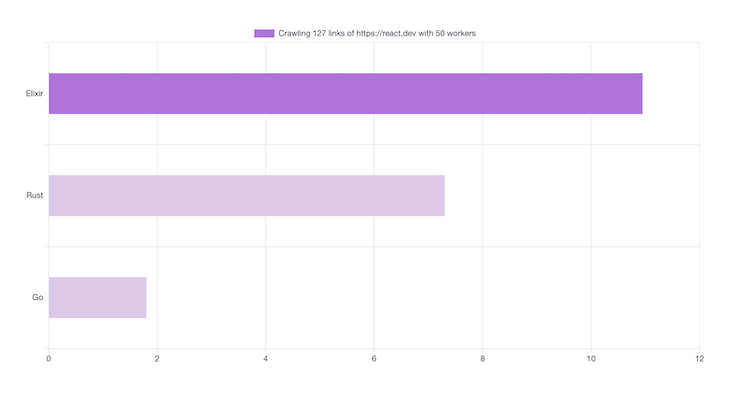
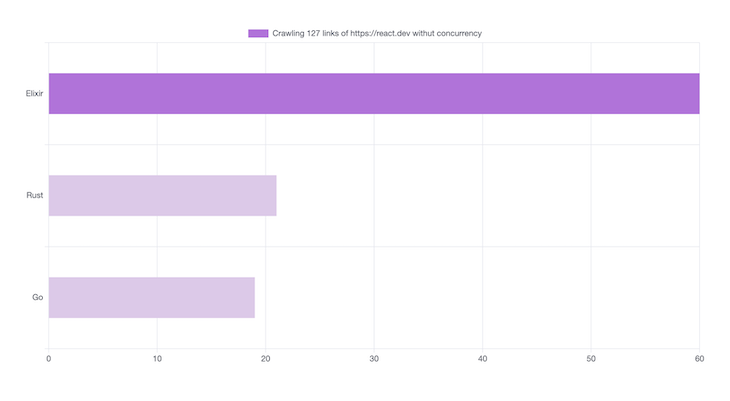
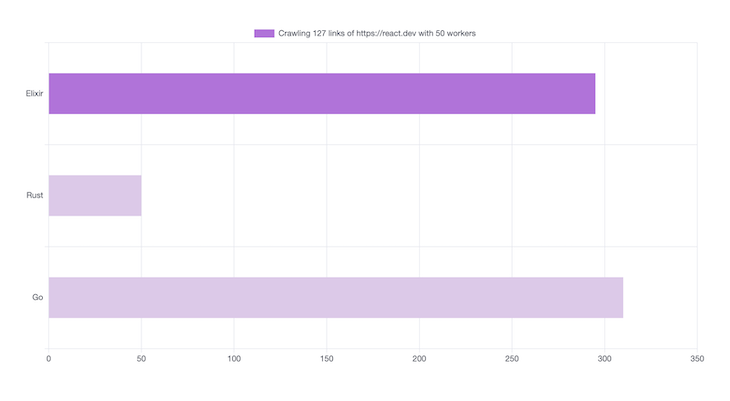
Tour of RUST #1
유용한 학습 사이트
Cargo project 만들기
바이너리 파일을 생성하는 프로젝트
$ cargo new [프로젝트명]
# Cargo.toml, main.rs 생성
라이브러리 파일을 생성하는 프로젝트
$ cargo new [프로젝트명] -lib
# Cargo.toml, lib.rs 가 생성
유용한 도구
rustfmt
- Rust 팀에서 개발, 관ㄹㅣ하고 있는 공식 포맷터(Formatter)
- 공식 스타일 가이드라인을 참고해서 자동으로 코드 스타일을 수정
cargo fmt
clippy
- Rust 팀에서 개발, 간리하고 있는 코드 린터 (Linter)
- 현재 코드의 문제점을 파악하고, 자동으로 수정할 수 있다.
cargo clippy
변수
let 키워드 사용
변수의 자료형을 대부분 유추할 수 있다.
변수 숨김(Variable Shadowing)을 지원
변수의 이름은 언제나 snake_case형태로 짓는다.
fn main() {
let x = 13;
println!("{}", x);
let x: f64 = 3.14159;
println!("{}", x);
let x;
x = 0;
println!("{}", x);
}
Rust에서 변수는 기본적으로 변경 불가(Immutable) 타입이다.
변경 가능(Mutable)한 값을 원한다면 mut키쿼드로 표시해줘야 한다.
fn main() {
let mux x = 42;
println!("{}", x);
x = 13;
println!("{}", x);
}
2. 기본 데이터 구조
기본 자료형
부울값: bool
부호가 없는 정수형: 양의 정수를 나타내는 u8, u16,u32, u64, u128
부호가 있는 정수형 - 양/음의 정수를 나타내는 i8, i16, i32, i64, i128
포인터 사이즈 정수: 메모리에 있는 값들의 인덱스와 크리를 나타내는 usize, isize
부동소수점: f32, f64
튜플(tuple): stack에 있는 값들의 고정된 순서를 전달하기 위한 (value, value, …)
배열(array): 컴파일 타임에 정해진 길이를 갖는 유사한 원소들의 모음(Collection)인 [value, value, …]
슬라이스(slice): 런타임에 길이가 정해지는 유사한 원소들의 collection
str(문자열 slice): 런타임에 길이가 정해지는 텍스트
자료형 변환을 할 때는 as 키워드를 사용한다. ( Rust에서는 숫자형 자료형을 쓸 때 명시적으로 사용해야 한다.)
fn main{
let a = 13u8;
let b = 7u32;
let c = a as u32 + b;
println!("{}", c);
let t = true;
println!("{}", t as u8);
}
상수
상수는 변수와 달리 반드시 명시적으로 자료형을 지정해야 한다.
상수의 이름은 언제나 SCREAMING_SNAKE_CASE형태로 짓는다.
const PI: f32 = 3.14159;
fn main() {
println!(
PI
);
}
배열
고정된 길이로 된 모든 같은 자료형의 자료를 갖는 Collection
[T; N]으로 표현한다.
T는 원소의 자료형n은 컴파일 타임에 주어지는 고정된 길이
각각의 원소는 [x] 연산자로 가져올 수 있다
fn main() {
let nums: [i32; 3] = [1,2,3];
println!("{:?}", nums);
println!("{}", nums[1]);
}
함수
함수의 0개 또는 그 이상의 인자를 가진다.
함수의 이름은 언제나 snake_case형태로 짓는다.
fn add(x: i32, y: i32) -> i32 {
return x + y;
}
fn main() {
println!("{}", add(42,13));
}
여러개의 리턴 값
함수에서 튜플(Tuple)을 리턴하면 여러개의 값을 리턴할 수 있다.
fn swap(x: i32, y: i32) -> (i32, i32) {
return (y, x);
}
fn main() {
let result = swap(123, 321);
println!("{} {}", result.0, result.1);
let (a,b,) = swap(result.0, result.1);
println!("{} {}", a, b);
}
아무것도 리턴하지 않기
함수에 리턴형을 지정하지 않는 경우 빈 튜플을 리턴하는데, ()로 표현한다.
fn make_nothing() -> () {
return ();
}
fn make_nothing2() {
// Do nothing
}
fn main() {
let a = make_nothing();
let b = make_nothing2();
pritnln!("The value of a: {:?}", a);
println!("The value of b: {:?}", b);
}
if/else if/else
조건문에 괄호가 없다
fn main() {
let x = 42;
if x < 42 {
println!("Less then 42");
} else if x == 42 {
println!("Eqeual 42");
} else {
println!("Greater than 42");
}
}
loop
무한 반복문이 필요할 때 사용
fn main() {
let mux x = 0;
loop {
x += 1;
if x == 49 {
break;
}
}
println!("{}", x);
}
while
반복문에 조건을 간단히 넣을 수 있다
조건의 평가 결과가 false인 경우, 종료한다.
fn main() {
let mux x = 0;
while x != 42 {
x += 1;
}
}
for
..연산자는 시작 숫자에서 끝 숫자 전까지의 숫자들을 생성하는 반복자를 만든다.
..=연산자는 시작 숫자에서 끝 숫자까지들을 생성하는 반복자를 만든다.
fn main() {
for x in 0..5 {
println!("{}", x);
}
for x in 0..=5 {
println!("{}", x);
}
}
match
switch를 대체하는 구문
모든 케이스를 빠짐없이 처리해야 한다.
fn main() {
let x = 41;
match x {
0 => {
println!("Foudn 0");
}
1 | 2 => {
println!("Fount 1 or 2!");
}
3..=9 => {
println!("Fount between 3 and 9!");
}
matched_num @ 10..=100 => {
println!("Fount {} between 10 and 100!", matched_num);
}
_ => {
println("Found something else!");
}
}
}
구조체
필드(Filed)들의 Collection
메모리 상에 필드들을 어떻게 배치할 지에 대한 컴파일러의 청사진
struct SeaCreature {
animal_type: String,
name: String,
arms: i32,
legs: i32,
weapon: String,
}
3. 기초적인 흐름 제어
메소드 호출하기
스태틱 메소드(Static Methods)
- 자료형 그 자체에 속하는 메소드
::연산자를 이용해 호출
인스턴스 메소드(Instance Methods)
- 자료형의 인스턴스에 속하는 메소드
.연산자를 이용해 호출
fn main() {
let s = String::from("Hello world!");
println!("The length of {} is {}.", s, s.len());
}
메모리에 데이터 생성하기
코드에서 구조체를 인스턴스화(Instaniate)하면 프로그램은 연관된 필드 데이터들을 메모리 상에 나란히 생성한다.
구조체의 필드값들은 .연산자를 통해 접근한다.
struct SeaCreature {
animal_type: String,
name: String,
arms: i32,
legs: i32,
weapon: String,
}
fn main() {
let ferris = SeaCreature {
animal_type: String::from("crab"),
name: String::from("Ferris"),
arms: 2,
legs: 4,
weapon: String::from("claw"),
}
열거형
enum키워드를 통해 몇 가지 태그된 원소의 값을 갖는 새로운 자료형을 생성할 수 있다
match와 함께 사용하면 품질 좋은 코드를 만들 수 있다.
enum Species {
Crab,
Octopus,
Fish,
Clam,
}
struct SeaCreature {
spcies: Species,
name; String,
}
fn main() {
let ferris = SeaCreate {
species: Species::Crab,
name: String::from("Ferris"),
}
match ferris.species {
Species::Crab => println("{} is Crab", ferries,name),
Species::Octopus => println("{} is Octopus", ferries,name),
Species::Fish => println("{} is Fish", ferries,name),
Species::Clam => println("{} is Clam", ferries,name),
}
}
4. Generic 자료형
Generic 자료형
struct나 enum을 부분적으로 정의해, 컴파일러가 컴파일 타임에 코드 사용을 기반으로 완전히 정의된 버전을 만들 수 있게 해준다.
struct BagOfHolding<T> {
item: T,
}
fn main() {
let i32_bag = BagOfHolding::<i32> { tiem: 42 };
let bool_bag = BagOfHolding::<bool> { item: true };
let float_bag = BagOfHolding { item: 3.14 };
let bag_in_bag = BagOfHolding {
item: BagOfHolding { item: "boom!" },
};
println!(
"{} {} {} {}",
i32_bag.item, bool_bag.item, float_bag.item, bag_in_bag.item.item
);
}
Option
null을 쓰지 않고도 Nullable한 값을 표현할 수 있는 내장된 Generic 열거체
enum Option<T> {
None,
Some(T),
}
struct BagOfHolding<T> {
item: Option<T>,
}
fn main() {
let i32_bag = BagOfHolding::<i32> { item: None };
if i32_bag.item.is_none() {
println!("Nothing!")
} else {
println!("Found Something!")
}
let i32_bag = BagOfHolding::<i32> { item: Some(42) };
if i32_bag.item.is_some() {
println!("Found Something!")
} else {
println!("Nothing!")
}
match i32_bag.item {
Some(v) => println!("Found {}!", v),
None => println!("Nothing!"),
}
}
Result
실패할 가능성이 있는 값을 리턴할 수 있도록 해주는 내장된 Genric 열거체
enum Result<T, E> {
Ok(T),
Err(E),
}
fn do_something_that_might_fail(i: i32) -> Result<f32, String> {
if i == 42 {
Ok(3.14)
} else {
Err(String::from("Not match!"))
}
}
fn main() {
let result = do_something_that_might_fail(12);
match result {
Ok(value) => println!("Success: {}", value),
Err(error) => println!("Error: {}", error),
}
}
우아한 오류 처리
Result와 함께 쓸 수 있는 강력한 연산자 ?
do_somrthing_that_might_fail()?
match do_something_that_might_fail() {
Ok(v) => v,
Err(e) => return Err(e),
}
fn do_something_that_might_fail(i: i32) -> Result<f32, String> {
if i == 42 {
Ok(13.0)
} else {
Err(String::from("Not match!"))
}
}
fn main() -> Result<(), String>{
let v = do_something_that_might_fail(42)?;
println!("Found {}", v);
Ok(())
}
추한 옵션/결과 처리
간단한 코드를 작성 할 때에도 Option/Result를 쓰는 것은 귀찮은 일일 수 있다
unwap이라는 함수를 사용해 빠르고 더러운 방식으로 값을 가져올 수 있다.
Option/Result 내부의 값을 꺼내오고enum이 None/Err인 경우에는 panic!
fn do_something_that_might_fail(i: i32) -> Result<f32, String> {
if i == 42 {
Ok(13.0)
} else {
Err(String::from("Not match!"))
}
}
fn main() -> Result<(), String> {
let v = do_something_that_might_fail(42).unwrap();
println!("Found {}", v);
let v = do_something_that_might_fail(1).unwrap();
println!("Found {}", v);
Ok(())
}
벡터
Vec구조체로 표현하는 가변 크기의 리스트Vec!머크로를 통해 손쉽게 생성할 수 있다.iter()메소드를 통해 반복자를 생성할 수 있다.
fn main() {
let mut float_vec = Vec::new();
float_vec.push(1.3);
float_vec.push(2.4);
float_vec.push(3.5);
let string_vec = vec![String::from("Hello"), String::from("World")];
for word in string_vec.iter() {
println!("{}", word);
}
}
5. 소유권과 데이터 대여
소유권 및 범위 기반 리소스 관리
자료형을 인스턴스화해 변수명에 할당(Binding)하면, Rust 컴파일러가 전체 생명주기(Lifetime) 동안 검증할 메모리 리소스를 생성한다.
할당된 변수는 리소스의 소유자(Owner)라고 한다.
Rust는 범위(scope)가 끌나는 곳에서 리소스를 소멸하고 할당 해제한다.
이 소멸과 할당 해제를 의미하는 용어로 drop을 사용한다. ( C++ 에서는 Resource Acquisition Is Initialization(RAII)라고 부른다)
구조체가 Drop될 때 구조체 자신이 제일 먼저 Drop되고, 이후 자식들이 각각 Drop된다.
소유권 이전
소유자가 함수의 인자로 전달되면, 소유권은 그 함수의 매개 변수로 이동(Move)된다.
이동된 이후에는 원래 함수에 있던 변수는 더 이상 사용할 수 없다.
struct Foo {
x: i32,
}
fn do_somerhing(f: foo) {
println!("{}", f.x);
}
fn main() {
let foo = Foo { x: 42 };
do_something(foo);
}
소유권 리턴하기
소유권은 함수에서도 리턴될 수 있다.
struct Foo {
x: i32,
}
fn do_somerhing() -> {
Foo {x: 42}
}
fn main() {
let foo = do_something(foo);
}
참조로 소유권 대여하기
&연산자를 통해 참조로 리소스에 대한 접근 권한을 대여할 수 있다
참조도 다른 리소스와 마찬가지로 Drop된다.
struct Foo {
x: i32,
}
fn main() {
let foo = Foo { x: 42};
let f = &foo;
println!("{}", f.x);
}
참조로 변경 가능한 소유권 대여하기
&mut연산자를 통해 리소스에 대해 변경 가능한 접근 권한도 대여할 수 있다.
리소스의 소유자는 변경 가능하게 대여된 상태에서 이동되거나 변경될 수 없다.
struct Foo {
x: i32,
}
fn do_something(f: Foo) {
println!("{}", f.x);
}
fn main() {
let mut foo = Foo { x:42 };
let f= &mut foo;
// do_something(foo); // error: use of moved value: `foo`
// foo.x = 13;
f.x = 13;
println!("{}", foo.x);
foo.x = 7;
do_something(foo);
}
역참조
&mut참조를 이용해 *연산자로 소유자의 값을 설정할 수 있다.
*연산자로 소유자의 값의 복사본도 가져올 수 있다.(복사 가능한 경우만)
fn main() {
let mut foo =42;
let f = &mut foo;
let bar = *f;
*f = 13;
println!("{}", bar);
println!("{}", foo);
}
대여한 데이터 전달하기
Rust의 참조 규칙
- 단 하나의 변경 가능한 참조 또는 여러개의 변경 불가능한 참조만 허용하며, 둘다는 안된다.
- 참조는 그 소유자보다 더 오래 살 수 없다.
보통 함수로 참조를 넘겨줄 때에는 문제가 되지 않는다.
struct Foo {
x: i32,
}
fn do_something(a: &Foo) -> &i32 {
return &a.x;
}
fn main() {
let mut foo = Foo { x: 42 };
let x = &mut foo.x;
*x = 13;
let y = do_something(&foo);
println!("{}", y);
}
명시적인 생명주기
Rust 컴파일러는 모든 변수의 생명 주기를 이해하며, 참조가 절대로 그 소유자보다 더 오래 존재하지 못하도록 검증을 시도한다.
함수에서 어떤 매개 변수와 리턴 값이 서로 같은 생명 주기를 공유하는지 식별할 수 있도록 심볼로 표시해 명시적으로 셩명 주기를 지정할 수 있다.
생명 주기 지정자는 언제나’로 시작한다. (ex: ‘a, ‘b, ‘c)
struct Foo {
x: i32,
}
fn do_something<'a>(foo: &'a Foo) -> &'a i32 {
return &foo.x;
}
fn main() {
let mut foo = Foo { x: 42 };
let x = &mut foo.x;
*x = 43;
let y = do_something(&foo);
println!("{}", y);
}
여러 개의 생명 주기
생명 주지 지정자는 컴파ㅊ일러가 스스로 함수 매개 변수들의 생명 주기를 판별하지 못하는 경우, 이를 명시적으로 지정할 수 있게 도와준다.
struct Foo {
x: i32,
}
fn do_something<'a, 'b>(foo_a: &'a Foo, foo_b: &'b Foo) -> &'b i32 {
println!("{}", foo_a.x);
println!("{}", foo_b.x);
return &foo_b.x;
}
fn main() {
let foo_a = Foo { x: 42 };
let foo_b = Foo { x: 12 };
let x = do_something(&foo_a, &foo_b);
println!("{}", x);
}
정적인 생명주기
static변수는 컴파일 타임에 생성되어 프로그램의 시작부터 끝까지 존재하는 메모리 리소스다. 이들은 명시적으로 자료형을 지정해 주어야 한다.
static생명 주기는 프로그램이 끝날 때까지 무한정 유지되는 메모리 리소스다. 따라서 static이라는 특별한 생명주기 지정자를 갖는다.
static한 리소스는 절대 drop 되지 않는다.
만약 static 생명 주기를 갖는 리소스가 참조를 포함하는 경우, 그들도 모두 static이어야 한다. (그 이하의 것들은 충분히 오래 살아남지 못한다)
static PI: f64 = 3.1415;
fn main() {
static mut SECRET: &'static str = "swordfish";
let msg: &'static str = "Hello World";
let p: &'static f64 = &PI;
println!("{} {} ", msg, p);
unsafe {
SECRET = "abracadbra";
println!("{}", SECRET);
}
}
데이터 자료형의 생명주기
함수와 마찬가지로 데이터 자료형의 구성원들도 생명 주기 지정자로 지정할 수 있다.
Rust는 참조가 품고 있는 데이터 구조가 참조가 가리키는 소유자보다 절대 오래 살아남지 못하도록 검증한다.
아무것도 아닌 것을 가리키는 참조를 들고 다니는 구조체는 있을 수 없다.
struct Foo<'a> {
i:&'a i32
}
fn main() {
let x = 42;
let foo = Foo {
i: &x
};
println!("{}", foo.i);
}