개요
이 실습에서는 다음 작업을 실행하는 방법을 학습합니다.
- Kubernetes Engine을 사용하여 완전한 Kubernetes 클러스터를 프로비저닝합니다.
kubectl을 사용하여 Docker 컨테이너를 배포하고 관리합니다.- Kubernetes의 디플로이먼트 및 서비스를 사용하여 애플리케이션을 마이크로서비스로 분할합니다.
Kubernetes는 애플리케이션에 중점을 둡니다. 이 실습 부분에서는 'app'이라는 예제 애플리케이션을 사용하여 실습을 완료합니다.
App은 Github에서 호스팅되며 12요소 예시 애플리케이션을 제공합니다. 이 실습에서는 다음 Docker 이미지를 다룹니다.
Kubernetes는 kubernetes.io에서 사용할 수 있는 오픈소스 프로젝트이며 노트북에서 고가용성 다중 노드 클러스터, 공용 클라우드에서 온프레미스 배포, 가상 머신에서 베어 메탈까지 다양한 환경에서 실행 가능합니다.
이 실습에서는 Kubernetes Engine과 같은 관리 환경을 사용하여 기본 인프라를 설정하기보다는 Kubernetes를 경험하는 데 집중합니다.
Google Kubernetes Engine
Cloud Shell 환경에서 다음 명령어를 입력하여 영역을 설정합니다. (5분 이상 소요)
$ gcloud config set compute/zone us-central1-b
Updated property [compute/zone].
$ gcloud container clusters create io
Default change: VPC-native is the default mode during cluster creation for versions greater than 1.21.0-gke.1500. To create advanced routes based clusters, please pass the `--no-enable-ip-alias` flag
Default change: During creation of nodepools or autoscaling configuration changes for cluster versions greater than 1.24.1-gke.800 a default location policy is applied. For Spot and PVM it defaults to ANY, and for all other VM kinds a BALANCED policy is used. To change the default values use the `--location-policy` flag.
Note: Your Pod address range (`--cluster-ipv4-cidr`) can accommodate at most 1008 node(s).
Creating cluster io in us-central1-b... Cluster is being deployed...working..
참고: Kubernetes Engine이 백그라운드에서 몇몇 가상 머신을 프로비저닝하고 있으므로 클러스터를 만드는 데 다소 시간이 걸립니다.
샘플 코드 가져오기
Cloud Shell 명령줄에서 GitHub 저장소를 클론합니다.
$ gsutil cp -r gs://spls/gsp021/* .
$ cd orchestrate-with-kubernetes/kubernetes
$ ls
deployments/ /* 디플로이먼트 매니페스트 */
...
nginx/ /* nginx 구성 파일 */
...
pods/ /* 포드 매니페스트 */
...
services/ /* 서비스 매니페스트 */
...
tls/ /* TLS 인증서 */
...
cleanup.sh /* 정리 스크립트 */
코드를 가져왔으므로 이제 Kubernetes를 사용해 보겠습니다.
간략한 Kubernetes 데모
Kubernetes를 시작하는 가장 쉬운 방법은 kubectl create 명령어를 사용하는 것입니다. 이를 사용하여 nginx 컨테이너의 단일 인스턴스를 실행합니다.
$ kubectl create deployment nginx --image=nginx:1.10.0
deployment.apps/nginx created
Kubernetes가 배포를 생성했습니다. 배포에 관해서는 나중에 다시 설명드리겠습니다. 지금 알아야 하는 점은 배포 덕분에 pod가 작동하고 있으며, pod가 실행하는 노드에 오류가 발생해도 계속해서 작동한다는 점입니다.
Kubernetes에서 모든 컨테이너는 포드에서 실행됩니다. kubectl get pods 명령어를 사용하여 실행 중인 nginx 컨테이너를 확인합니다.
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-68899cc8d6-mbxms 1/1 Running 0 30s
nginx 컨테이너가 실행되면 kubectl expose 명령어를 사용하여 Kubernetes 외부로 노출시킬 수 있습니다.
$ kubectl expose deployment nginx --port 80 --type LoadBalancer
service/nginx exposed
방금 무슨 일이 일어났을까요? Kubernetes가 백그라운드에서 공개 IP 주소가 첨부된 외부 부하 분산기를 만들었습니다. 이 공개 IP 주소를 조회하는 모든 클라이언트는 서비스 백그라운드에 있는 포드로 라우팅됩니다. 이 경우에는 nginx 포드로 라우팅됩니다.
이제 kubectl get services 명령어를 사용하여 서비스를 나열합니다.
$ kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.72.0.1 <none> 443/TCP 3m29s
nginx LoadBalancer 10.72.13.84 <pending> 80:31884/TCP 3s
참고: 서비스를 위해 ExternalIP 필드가 채워지는 데는 몇 초 정도 소요될 수 있습니다. 이는 정상적인 현상입니다. 필드가 채워질 때까지 몇 초마다 kubectl get services 명령어를 다시 실행합니다.
원격으로 Nginx 컨테이너를 조회하려면 이 명령어에 외부 IP를 추가합니다.
curl http://<External IP>:80
이제 됐습니다. Kubernetes는 kubectl 실행 및 노출 명령어로 바로 사용할 수 있는 간편한 워크플로를 지원합니다.
포드
Kubernetes의 핵심에는 포드가 있습니다.
포드는 1개 이상의 컨테이너가 포함된 모음을 나타냅니다. 일반적으로 상호 의존성이 높은 컨테이너가 여러 개 있으면 이를 하나의 포드에 패키징합니다.
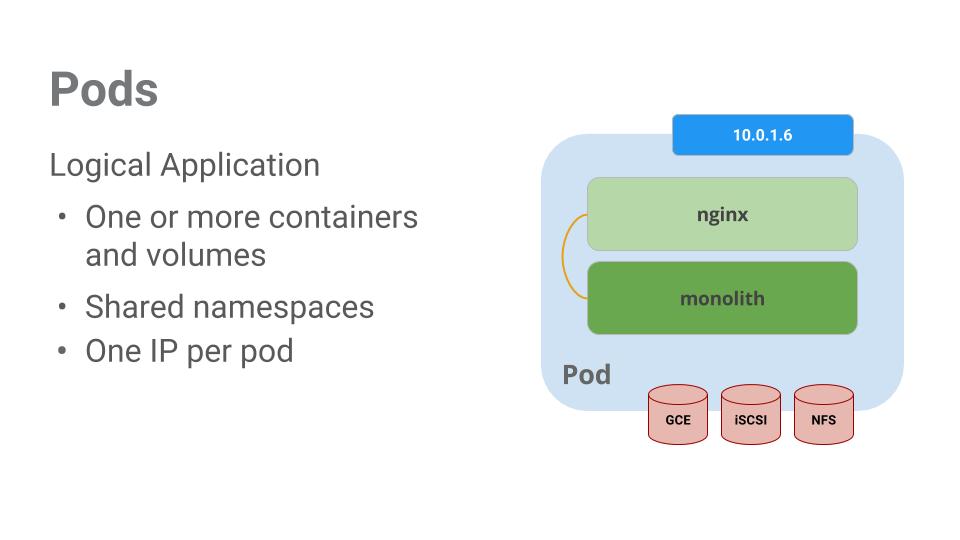
이 예시에는 모놀리식 및 nginx 컨테이너가 포함된 포드가 있습니다.
포드에는 볼륨 또한 포함되어 있습니다. 볼륨은 포드가 존재하는 한 계속해서 존재하는 데이터 디스크이며 포드에 포함된 컨테이너에 의해 사용될 수 있습니다. 포드는 콘텐츠에 공유된 네임스페이스를 제공합니다. 즉, 이 예시의 포드 안에 있는 2개의 컨테이너는 서로 통신할 수 있으며 첨부된 볼륨도 공유합니다.
또한 포드는 네트워크 네임스페이스도 공유합니다. 즉, 포드는 IP 주소를 1개씩 갖고 있습니다.
이제 포드에 관해 더 자세히 살펴보겠습니다.
포드 만들기
포드는 포드 구성 파일을 사용하여 만들 수 있습니다. 모놀리식 포드 구성 파일을 살펴보겠습니다. 다음을 실행해 보세요.
cat pods/monolith.yaml
열린 구성 파일이 출력됩니다.
apiVersion: v1
kind: Pod
metadata:
name: monolith
labels:
app: monolith
spec:
containers:
- name: monolith
image: kelseyhightower/monolith:1.0.0
args:
- "-http=0.0.0.0:80"
- "-health=0.0.0.0:81"
- "-secret=secret"
ports:
- name: http
containerPort: 80
- name: health
containerPort: 81
resources:
limits:
cpu: 0.2
memory: "10Mi"
여기서 주목해야 할 부분이 몇 군데 있습니다. 다음과 같은 부분을 확인합니다.
- 포드가 1개의 컨테이너(모놀리식)로 구성되어 있습니다.
- 시작할 때 컨테이너로 몇 가지 인수가 전달됩니다.
- HTTP 트래픽용 포드 80이 개방됩니다.
kubectl을 사용하여 모놀리식 포드를 만듭니다.
$ kubectl create -f pods/monolith.yaml
pod/monolith created
포드를 살펴보세요. kubectl get pods 명령어를 사용하여 기본 네임스페이스에서 실행 중인 모든 포드를 나열합니다.
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
monolith 1/1 Running 0 5s
nginx-68899cc8d6-mbxms 1/1 Running 0 6m31s
참고: 모놀리식 pod가 작동하는 데는 몇 초 정도 걸릴 수 있습니다. 이를 실행하기 위해 Docker Hub에서 모놀리식 컨테이너 이미지를 가져와야 합니다.
포드가 실행되면 kubectl describe 명령어를 사용하여 모놀리식 포드에 관해 자세히 알아봅니다.
$ kubectl describe pods monolith
Name: monolith
Namespace: default
Priority: 0
Service Account: default
Node: gke-io-default-pool-0935d588-wsgq/10.128.0.5
Start Time: Mon, 17 Apr 2023 14:31:07 +0000
Labels: app=monolith
Annotations: <none>
Status: Running
IP: 10.68.2.6
IPs:
IP: 10.68.2.6
Containers:
monolith:
Container ID: containerd://0e1480aa970c23e1a20a2a27ae023c38fc89aac8999863eeebd2d8689efcbc13
student_01_1d660bd4cf04@cloudshell:~ (qwiklabs-gcp-04-750f8d78df82)$ kubectl describe pods monolith
Name: monolith
Namespace: default
Priority: 0
Service Account: default
Node: gke-io-default-pool-0935d588-wsgq/10.128.0.5
Start Time: Mon, 17 Apr 2023 14:31:07 +0000
Labels: app=monolith
Annotations: <none>
Status: Running
IP: 10.68.2.6
IPs:
IP: 10.68.2.6
Containers:
monolith:
Container ID: containerd://0e1480aa970c23e1a20a2a27ae023c38fc89aac8999863eeebd2d8689efcbc13
Image: kelseyhightower/monolith:1.0.0
Image ID: sha256:980e09dd5c76f726e7369ac2c3aa9528fe3a8c92382b78e97aa54a4a32d3b187
Ports: 80/TCP, 81/TCP
Host Ports: 0/TCP, 0/TCP
Args:
-http=0.0.0.0:80
-health=0.0.0.0:81
-secret=secret
State: Running
Started: Mon, 17 Apr 2023 14:31:11 +0000
Ready: True
Restart Count: 0
Limits:
cpu: 200m
memory: 10Mi
Requests:
cpu: 200m
memory: 10Mi
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-z5vc8 (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
kube-api-access-z5vc8:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
QoS Class: Guaranteed
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 85s default-scheduler Successfully assigned default/monolith to gke-io-default-pool-0935d588-wsgq
Normal Pulling 83s kubelet Pulling image "kelseyhightower/monolith:1.0.0"
Normal Pulled 81s kubelet Successfully pulled image "kelseyhightower/monolith:1.0.0" in 1.623212676s
Normal Created 81s kubelet Created container monolith
Normal Started 81s kubelet Started container monolith
포드 IP 주소 및 이벤트 로그를 포함한 모놀리식 포드에 관한 여러 정보가 표시됩니다. 이 정보는 문제해결 시 유용하게 사용됩니다.
Kubernetes를 사용하면 구성 파일에 포드에 관해 설명하여 간편하게 포드를 만들 수 있으며, 포드가 실행 중일 때 정보를 쉽게 확인할 수 있습니다. 이제 디플로이먼트에 필요한 모든 포드를 만들 수 있습니다.
포드와 상호작용하기
포드에는 기본적으로 비공개 IP 주소가 부여되며 클러스터 밖에서는 접근할 수 없습니다. kubectl port-forward 명령어를 사용하여 로컬 포트를 모놀리식 포드 안의 포트로 매핑합니다.
이 시점부터 포드 간 통신을 설정하기 위해 실습이 여러 Cloud Shell 탭에서 진행됩니다. 두 번째 또는 세 번째 명령어 셸에서 실행되는 명령어는 명령어 안내에 표시됩니다.
Cloud Shell 터미널 2개를 엽니다. 하나는 kubectl port-forward 명령어를 실행하고 다른 하나는 curl 명령어를 실행하기 위한 것입니다.
두 번째 터미널에서 다음 명령어를 사용하여 포드 전달을 설정합니다.
$ kubectl port-forward monolith 10080:80
Forwarding from 127.0.0.1:10080 -> 80
Handling connection for 10080
첫 번째 터미널에서 curl을 사용하여 pod와 통신을 시작합니다.
$ curl http://127.0.0.1:10080
{"message":"Hello"}
성공입니다. 컨테이너가 친절하게도 'hello'라고 인사를 건넵니다.
이제 curl 명령어를 사용하여 보안이 설정된 엔드포인트를 조회하면 어떻게 되는지 살펴보겠습니다.
$ curl http://127.0.0.1:10080/secure
authorization failed
문제가 발생했습니다.
모놀리식에서 다시 인증 토큰을 얻기 위해 로그인을 시도합니다.
$ curl -u user http://127.0.0.1:10080/login
Enter host password for user 'user':
{"token":"eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJlbWFpbCI6InVzZXJAZXhhbXBsZS5jb20iLCJleHAiOjE2ODIwMDEzMDQsImlhdCI6MTY4MTc0MjEwNCwiaXNzIjoiYXV0aC5zZXJ2aWNlIiwic3ViIjoidXNlciJ9.3dlmkdzGseb2HqgR6IVVrwcTRpmrHLJ5ItgNIi_N7CE"}
로그인 메시지에서 일급 비밀번호인 'password'를 사용하여 로그인합니다.
로그인하여 JWT 토큰이 출력되었습니다. Cloud Shell은 긴 문자열을 제대로 복사하지 못하니 토큰을 위한 환경 변수를 만듭니다.
$ TOKEN=$(curl http://127.0.0.1:10080/login -u user|jq -r '.token')
호스트 비밀번호를 묻는 메시지가 나타나면 일급 비밀번호 'password'를 다시 입력합니다.
다음 명령어를 사용하여 토큰을 복사하고, 이 토큰으로 curl을 사용하여 보안이 설정된 엔드포인트를 조회합니다.
$ curl -H "Authorization: Bearer $TOKEN" http://127.0.0.1:10080/secure
{"message":"Hello"}
이제 애플리케이션으로부터 모두 제대로 작동한다는 응답이 전송될 것입니다.
kubectl logs 명령어를 사용하여 monolith 포드의 로그를 확인합니다.
$ kubectl logs monolith
세 번째 터미널을 열고 -f 플래그를 사용하여 실시간 로그 스트림을 가져옵니다.
$ kubectl logs -f monolith
첫 번째 터미널에서 curl을 사용하여 모놀리식 pod와 상호작용했다면 세 번째 터미널에서 로그가 업데이트되는 것을 확인할 수 있습니다.
# curl http://127.0.0.1:10080
kubectl exec 명령어를 사용하여 모놀리식 포드의 대화형 셸을 실행합니다. 이는 컨테이너 내부에서 문제를 해결할 때 유용합니다.
$ kubectl exec monolith --stdin --tty -c monolith /bin/sh
예를 들어 모놀리식 컨테이너에 셸이 있으면 ping 명령어를 사용하여 외부 연결을 테스트할 수 있습니다.
$ ping -c 3 google.com
대화형 셸 사용을 완료한 후에는 반드시 로그아웃합니다.
$ exit
이와 같이 포드와의 상호작용은 kubectl 명령을 사용하는 것만큼 쉽습니다. 원격으로 컨테이너를 조회하거나 로그인 셸이 필요한 경우 Kubernetes가 작업에 필요한 모든 것을 제공합니다.
서비스
포드는 영구적으로 지속되지 않습니다. 활성 여부 또는 준비 상태 검사 오류와 같은 다양한 이유로 중지되거나 시작될 수 있으며, 이로 인해 문제가 발생합니다.
포드 집합과 통신해야 하는 경우 어떻게 해야 할까요? 포드가 다시 시작되면 IP 주소가 바뀔 수도 있습니다.
이와 같은 상황에서 서비스가 유용합니다. 서비스는 포드를 위해 안정적인 엔드포인트를 제공합니다.
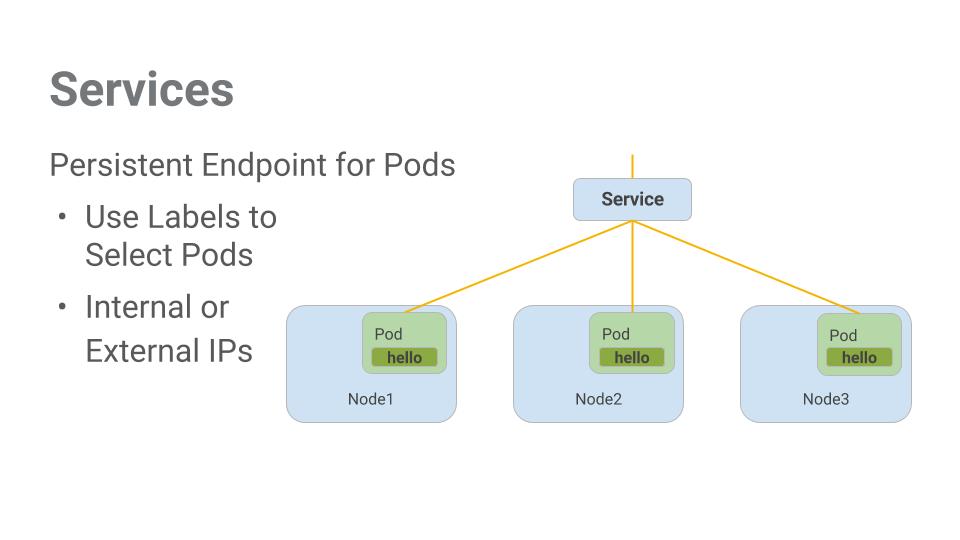
서비스는 라벨을 사용하여 어떤 포드에서 작동할지 결정합니다. 포드에 라벨이 정확히 지정되어 있다면 서비스가 이를 자동으로 감지하고 노출시킵니다.
서비스가 제공하는 포드 집합에 대한 액세스 수준은 서비스 유형에 따라 다릅니다. 현재 3가지 유형이 있습니다.
ClusterIP(내부) -- 기본 유형이며 이 서비스는 클러스터 안에서만 볼 수 있습니다.NodePort 클러스터의 각 노드에 외부에서 액세스 가능한 IP 주소를 제공합니다.LoadBalancer는 클라우드 제공업체로부터 부하 분산기를 추가하며 서비스에서 유입되는 트래픽을 내부에 있는 노드로 전달합니다.
이제 다음 작업을 실행하는 방법을 학습합니다.
- 서비스 만들기
- 라벨 셀랙터를 사용하여 제한된 포드 집합을 외부에 노출하기
서비스 만들기
서비스를 만들기 전에 https 트래픽을 처리할 수 있는 보안이 설정된 포드를 만듭니다.
디렉토리를 수정했을 경우 ~/orchestrate-with-kubernetes/kubernetes 디렉토리로 다시 돌아갑니다.
cd ~/orchestrate-with-kubernetes/kubernetes
모놀리식 서비스 구성 파일을 살펴봅니다.
cat pods/secure-monolith.yaml
보안이 설정된 모놀리식 포드와 구성 데이터를 만듭니다.
$ kubectl create secret generic tls-certs --from-file tls/
secret/tls-certs created
$ kubectl create configmap nginx-proxy-conf --from-file nginx/proxy.conf
configmap/nginx-proxy-conf created
$ kubectl create -f pods/secure-monolith.yaml
pod/secure-monolith created
이제 보안이 설정된 포드가 있으니 이를 외부로 노출시킵니다. 이렇게 하기 위해 Kubernetes 서비스를 만듭니다.
모놀리식 서비스 구성 파일을 살펴봅니다.
cat services/monolith.yaml
(출력):
kind: Service
apiVersion: v1
metadata:
name: "monolith"
spec:
selector:
app: "monolith"
secure: "enabled"
ports:
- protocol: "TCP"
port: 443
targetPort: 443
nodePort: 31000
type: NodePort
참고
app: monolith 및 secure: enabled 라벨이 지정된 포드를 자동으로 찾고 노출시키는 선택기가 있습니다.- 외부 트래픽을 포트 31000에서 포트 443의 nginx로 전달하기 위해 NodePort를 노출시켜야 합니다.
kubectl create 명령어를 사용하여 모놀리식 서비스 구성 파일에서 모놀리식 서비스를 만듭니다.
$ kubectl create -f services/monolith.yaml
service/monolith created
서비스 노출 시에는 pod가 사용됩니다. 즉, 다른 앱이 서버 중 하나의 포트 31000과 연결을 시도하면 포트 충돌이 발생할 수 있습니다.
일반적으로 포트 할당은 Kubernetes가 처리합니다. 이 실습에서는 포트를 선택했기 때문에 추후 더 쉽게 상태 확인을 설정할 수 있습니다.
gcloud compute firewall-rules 명령어를 사용하여 트래픽을 노출된 NodePort의 모놀리식 서비스로 보냅니다.
$ gcloud compute firewall-rules create allow-monolith-nodeport --allow=tcp:31000
Creating firewall...working..Created [https://www.googleapis.com/compute/v1/projects/qwiklabs-gcp-04-750f8d78df82/global/firewalls/allow-monolith-nodeport].
Creating firewall...done.
NAME: allow-monolith-nodeport
NETWORK: default
DIRECTION: INGRESS
PRIORITY: 1000
ALLOW: tcp:31000
DENY:
DISABLED: False
이제 설정이 완료되었으니 포트 전달 없이 클러스터 밖에서 안전한 모놀리식 서비스를 조회할 수 있습니다.
먼저 노드 1개의 외부 IP 주소를 가져옵니다.
$ gcloud compute instances list
NAME: gke-io-default-pool-0935d588-2p36
ZONE: us-central1-b
MACHINE_TYPE: e2-medium
PREEMPTIBLE:
INTERNAL_IP: 10.128.0.4
EXTERNAL_IP: 35.202.160.183
STATUS: RUNNING
NAME: gke-io-default-pool-0935d588-wnl3
ZONE: us-central1-b
MACHINE_TYPE: e2-medium
PREEMPTIBLE:
INTERNAL_IP: 10.128.0.3
EXTERNAL_IP: 35.184.250.47
STATUS: RUNNING
NAME: gke-io-default-pool-0935d588-wsgq
ZONE: us-central1-b
MACHINE_TYPE: e2-medium
PREEMPTIBLE:
INTERNAL_IP: 10.128.0.5
EXTERNAL_IP: 34.122.69.115
STATUS: RUNNING
이제 curl을 사용하여 보안이 설정된 모놀리식 서비스를 조회해 봅니다.
$ curl -k https://<EXTERNAL_IP>:31000
이런! 시간이 초과되었습니다. 왜 그럴까요?
이제 배운 내용을 간단하게 확인해 보겠습니다.
다음 명령어를 사용하여 아래 질문에 답하세요.
$ kubectl get services monolith
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
monolith NodePort 10.72.15.207 <none> 443:31000/TCP 5m29s
$ kubectl describe services monolith
Name: monolith
Namespace: default
Labels: <none>
Annotations: cloud.google.com/neg: {"ingress":true}
Selector: app=monolith,secure=enabled
Type: NodePort
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.72.15.207
IPs: 10.72.15.207
Port: <unset> 443/TCP
TargetPort: 443/TCP
NodePort: <unset> 31000/TCP
Endpoints: <none>
Session Affinity: None
External Traffic Policy: Cluster
Events: <none>
질문:
- 모놀리식 서비스가 응답하지 않은 이유는 무엇인가요?
- 모놀리식 서비스는 몇 개의 엔드포인트를 가지고 있나요?
- 모놀리식 서비스가 포드를 감지하게 하려면 포드에 어떤 라벨이 지정되어 있어야 하나요?
힌트: 라벨에 관한 질문입니다. 다음 섹션에서 이 문제를 해결하겠습니다.
포드에 라벨 추가하기
현재 모놀리식 서비스에는 엔드포인트가 없습니다. 이와 같은 문제를 해결하는 방법 중 하나는 라벨 쿼리와 함께 kubectl get pods 명령어를 사용하는 것입니다
모놀리식 라벨이 지정되어 실행되는 포드 몇 개가 있다는 사실을 확인할 수 있습니다.
$ kubectl get pods -l "app=monolith"
NAME READY STATUS RESTARTS AGE
monolith 1/1 Running 0 20m
secure-monolith 2/2 Running 0 8m13s
그런데 'app=monolith'와 'secure=enabled'는 어떤가요?
$ kubectl get pods -l "app=monolith,secure=enabled"
No resources found in default namespace.
이 라벨 쿼리로는 결과가 출력되지 않습니다. 'secure=enabled' 라벨을 추가해야 할 것 같습니다.
kubectl label 명령어를 사용하여 보안이 설정된 모놀리식 포드에 누락된 secure=enabled 라벨을 추가합니다. 그런 다음 라벨이 업데이트되었는지 확인합니다.
$ kubectl label pods secure-monolith 'secure=enabled'
pod/secure-monolith labeled
$ kubectl get pods secure-monolith --show-labels
NAME READY STATUS RESTARTS AGE LABELS
secure-monolith 2/2 Running 0 8m55s app=monolith,secure=enabled
이제 포드에 정확한 라벨을 지정했으니 모놀리식 서비스의 엔드포인트 목록을 확인합니다.
$ kubectl describe services monolith | grep Endpoints
Endpoints: 10.68.0.7:443
엔드포인트가 하나 있습니다.
노드 중 하나를 조회하여 이 엔드포인트를 테스트해 보겠습니다.
$ gcloud compute instances list
$ curl -k https://<EXTERNAL_IP>:31000
{"message":"Hello"}
좋습니다. 성공입니다.
Kubernetes로 애플리케이션 배포하기
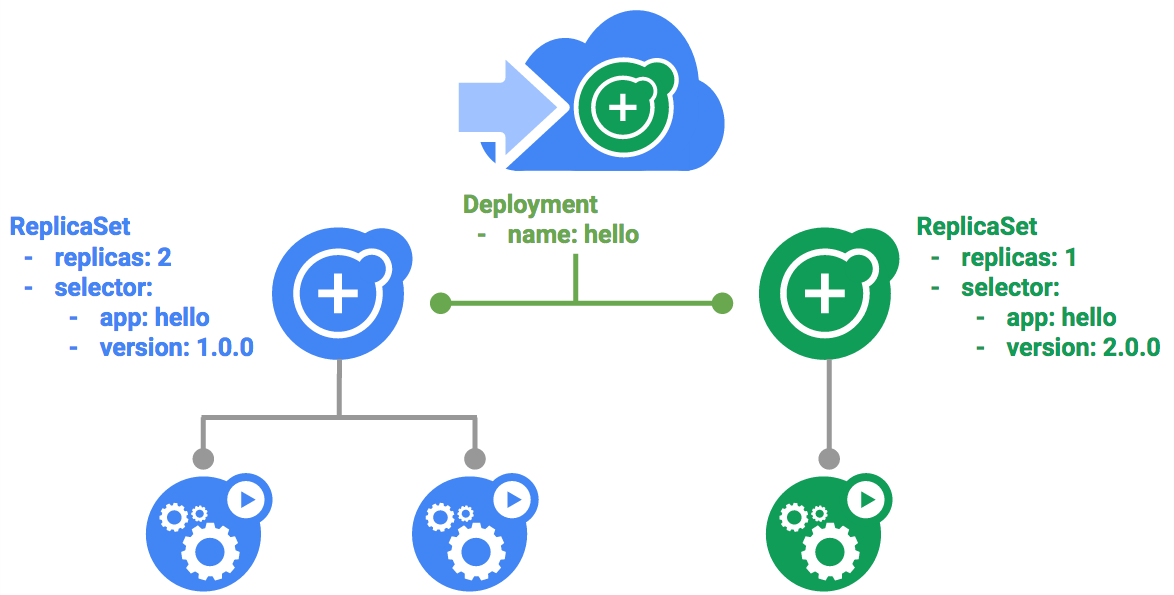
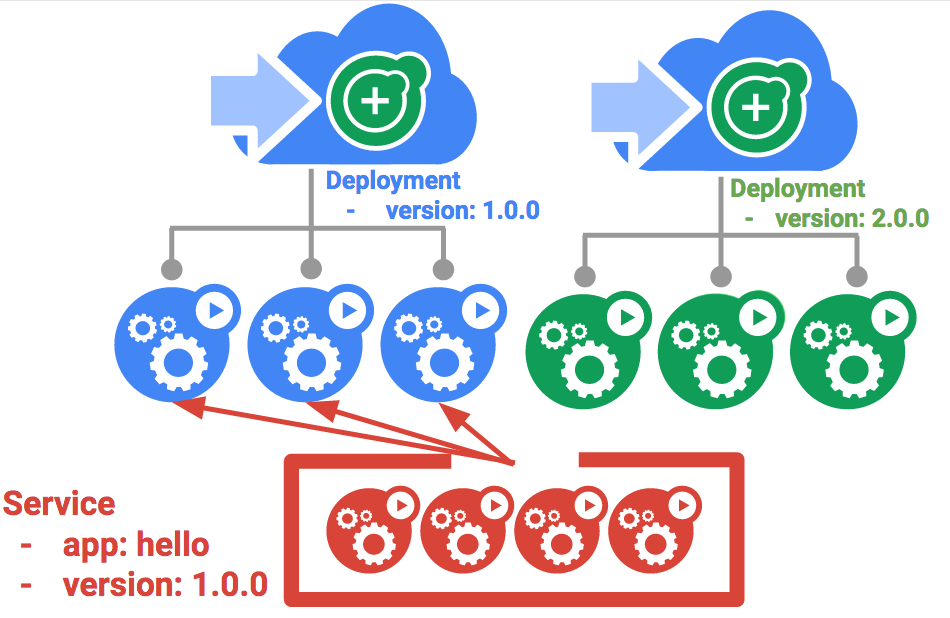
이 실습의 목표는 프로덕션의 컨테이너를 확장하고 관리하는 것입니다. 이와 같은 상황에서 디플로이먼트가 유용합니다. 디플로이먼트는 실행 중인 포드의 개수가 사용자가 명시한 포드 개수와 동일하게 만드는 선언적 방식입니다.
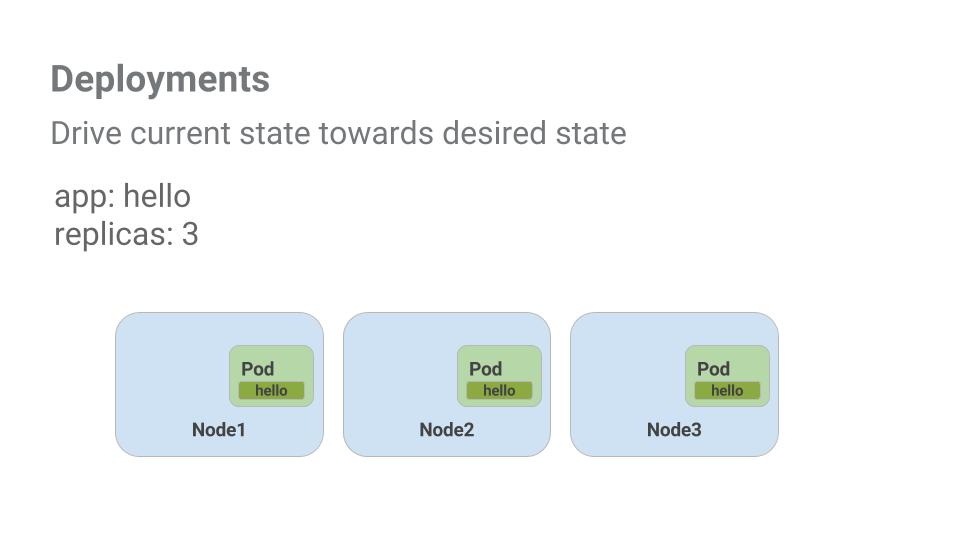 배포의 주요 이점은 pod 관리에서 낮은 수준의 세부정보를 추상화하는 데 있습니다. 배포는 백그라운드에서 복제본 집합을 사용하여 pod의 시작 및 중지를 관리합니다. Pod를 업데이트하거나 확장해야 하는 경우 배포가 이를 처리합니다. 또한 디플로이먼트는 어떤 이유로든 포드가 중지되면 재시작을 담당하여 처리합니다.
배포의 주요 이점은 pod 관리에서 낮은 수준의 세부정보를 추상화하는 데 있습니다. 배포는 백그라운드에서 복제본 집합을 사용하여 pod의 시작 및 중지를 관리합니다. Pod를 업데이트하거나 확장해야 하는 경우 배포가 이를 처리합니다. 또한 디플로이먼트는 어떤 이유로든 포드가 중지되면 재시작을 담당하여 처리합니다.
간단한 예를 살펴보겠습니다.
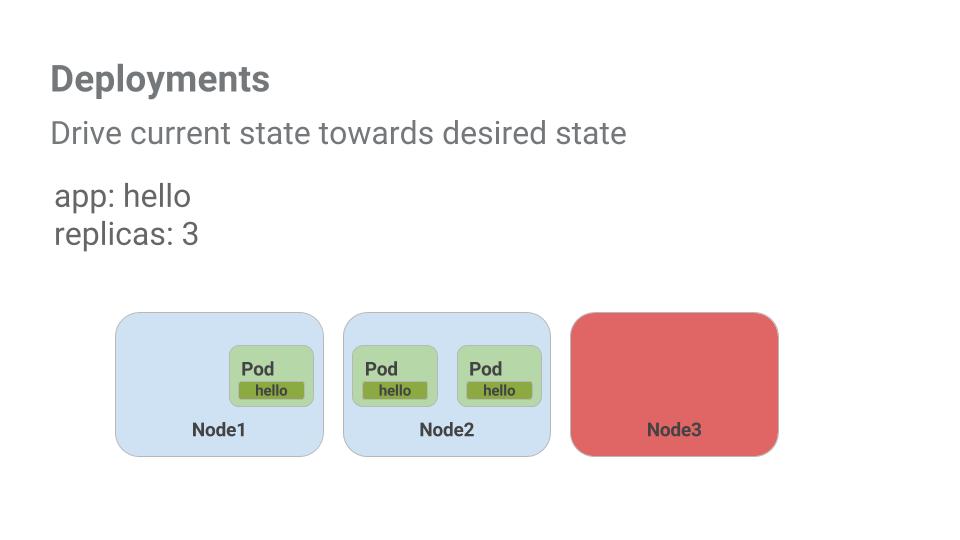
포드는 생성 기반 노드의 전체 기간과 연결되어 있습니다. 위 예시에서 Node3이 중단되면서 포드도 중단되었습니다. 직접 새로운 포드를 만들고 이를 위한 노드를 찾는 대신, 디플로이먼트가 새로운 포드를 만들고 Node2에서 실행했습니다.
아주 편리한 방식입니다.
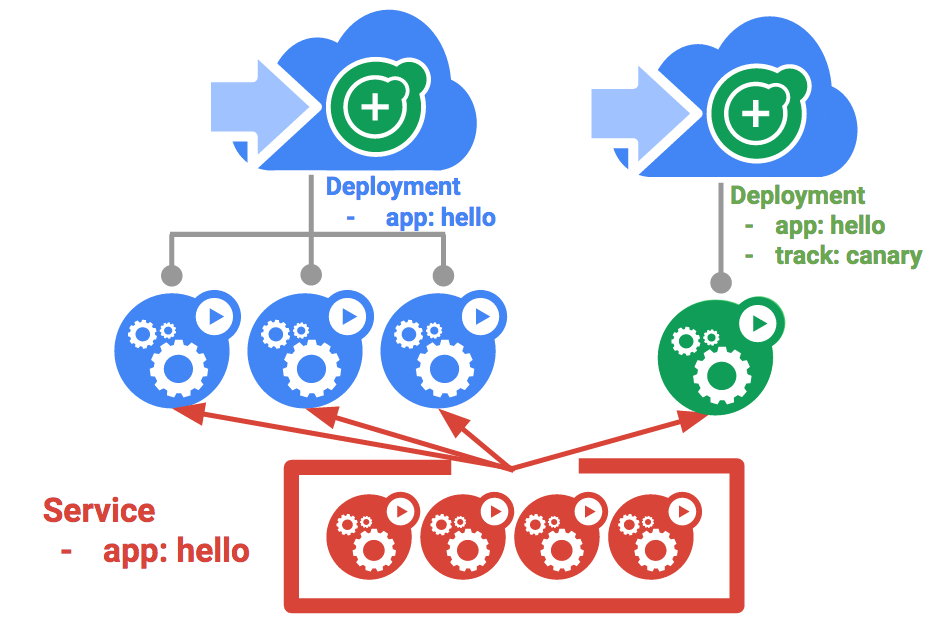
포드와 서비스에 관해 배운 모든 지식을 바탕으로, 이제 디플로이먼트를 사용하여 모놀리식 애플리케이션을 작은 서비스로 분할해 보겠습니다.
디플로이먼트 만들기
모놀리식 앱을 다음의 3가지 부분으로 나눕니다.
- auth - 인증된 사용자를 위한 JWT 토큰을 생성합니다.
- hello - 인증된 사용자를 안내합니다.
- frontend - 트래픽을 auth 및 hello 서비스로 전달합니다.
각 서비스용 디플로이먼트를 만들 준비가 됐습니다. 그런 다음 auth 및 hello 디플로이먼트용 내부 서비스와 frontend 디플로이먼트용 외부 서비스를 정의하겠습니다. 이렇게 하면 모놀리식과 같은 방식으로 마이크로서비스와 상호작용할 수 있으며, 각 서비스를 독립적으로 확장하고 배포할 수 있습니다.
auth 디플로이먼트 구성 파일을 검토하는 것으로 시작하겠습니다.
cat deployments/auth.yaml
(출력)
apiVersion: apps/v1
kind: Deployment
metadata:
name: auth
spec:
selector:
matchlabels:
app: auth
replicas: 1
template:
metadata:
labels:
app: auth
track: stable
spec:
containers:
- name: auth
image: "kelseyhightower/auth:2.0.0"
ports:
- name: http
containerPort: 80
- name: health
containerPort: 81
...
디플로이먼트가 복제본 1개를 만들며, 여기서는 auth 컨테이너 2.0.0 버전을 사용합니다.
kubectl create 명령어를 실행하여 auth 디플로이먼트를 만들면 디플로이먼트 매니페스트 데이터를 준수하는 포드가 만들어집니다. 즉, 복제본 필드에 명시된 숫자를 변경하여 포드 숫자를 조정할 수 있습니다.
이제 디플로이먼트 개체를 만듭니다.
$ kubectl create -f deployments/auth.yaml
deployment.apps/auth created
또한 auth 디플로이먼트용 서비스를 만듭니다. kubectl create 명령어를 사용하여 auth 서비스를 만듭니다.
$ kubectl create -f services/auth.yaml
service/auth created
hello 디플로이먼트 만들기와 노출도 위와 동일하게 진행합니다.
$ kubectl create -f deployments/hello.yaml
$ kubectl create -f services/hello.yaml
frontend 디플로이먼트 만들기와 노출 또한 위와 동일하게 진행합니다.
$ kubectl create configmap nginx-frontend-conf --from-file=nginx/frontend.conf
configmap/nginx-frontend-conf created
$ kubectl create -f deployments/frontend.yaml
deployment.apps/frontend created
$ kubectl create -f services/frontend.yaml
service/frontend created
frontend를 만들기 위해 컨테이너에 구성 데이터를 보관해야 하기 때문에 추가 단계를 진행합니다.
외부 IP 주소를 확보하고 curl 명령어를 사용하여 frontend와 상호작용합니다.
$ kubectl get services frontend
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
frontend LoadBalancer 10.72.5.5 <pending> 443:32585/TCP 12s
참고: 외부 IP 주소가 생성되는 데 1분 정도 걸릴 수 있습니다. EXTERNAL-IP 열 상태가 보류 중인 경우 위의 명령을 다시 실행합니다.
$ curl -k https://<EXTERNAL-IP>
{"message":"Hello"}
그러면 hello 응답을 받게 됩니다.


퀘스트 완료하기
이 사용자 주도형 실습은 Qwiklabs Cloud Architecture 및 Kubernetes in the Google Cloud 퀘스트의 일부입니다. 퀘스트는 교육 과정을 구성하는 일련의 관련 실습입니다. 이 퀘스트를 완료하면 위의 배지를 얻고 수료를 인증할 수 있습니다. 배지를 공개하고 온라인 이력서 또는 소셜 미디어 계정에 연결할 수 있습니다. 이 실습을 완료했다면 퀘스트에 등록하여 즉시 수료 크레딧을 받으세요. 다른 Qwiklabs 퀘스트도 참조해 보세요.
Kubernetes 기술을 시연하고 지식을 검증 할 실습 챌린지 랩을 찾고 계십니까? 이 퀘스트를 완료하면이 추가 챌린지 실습을 완료하여 독점 Google Cloud 디지털 배지를 받으세요.
다음 실습 참여하기
다음 실습 중 하나를 통해 퀘스트를 계속 진행하세요.